-
Zookeeper 클러스터 및 컨트롤러 선출Kafka 2021. 9. 19. 01:47반응형
1) 서론
간단하게 zookeeper 3개의 서버를 실행시켜 클러스터로 만듭니다. 그리고 zookeeper에 등록되는 컨트롤러 브로커의 장애 발생 시 어떻게 되는지 살펴봅니다.
+) 공부하는 입장에서 작성하는 "Hello World" 수준의 글입니다. 내용에 잘 못된 점이 있다면, 언제든지 댓글 남겨주세요!
2) Zookeeper
zookeeper는 분산 애플리케이션들의 관리를 도와주는 역할을 합니다.
개발자로 하여금 비즈니스 로직에만 집중할 수 있게 하고, 클라이언트(kafka) 관리는 zookeeper가 대신해줍니다. 만약 zookeeper가 관리해주지 않는다면, 거대한 클러스터 애플리케이션의 설정과 동기화 등을 직접 관리해야 할 겁니다.
kafka와 연동하여 서비스할 때 아래의 동작을 하게 됩니다.
- kafka 브로커 상태 관리
- 컨트롤러 브로커 선출
- ACL(Acess Control List) (브로커의 권한)
- 토픽 설정 (파티션 개수, replicas 위치 등)
위와 같이 zookeeper는 kafka 클러스터 관리를 위해 많은 일을 하게 되는데요. 그렇기 때문에 kafka 실행 전 zookeeper 서버를 먼저 실행합니다.
(공식 문서에 따르면, 카프카 2.8.0 버전부터 주키퍼 없이도 클러스터를 구성하고, 운영할 수 있게 한다고 합니다. 다만 실제 서비스에서 사용하기에는 아직 추천하지 않는다고 합니다)
특징은 zookeeper 스스로 클러스터화 되어 앙상블(ensemble)로 운영할 수 있습니다. 서비스들을 관리해주는 이렇게 중요한 것이 하나만 운영되면서, 장애가 발생하면 모든 서비스가 죽는 것은 끔찍합니다. 그래서 zookeeper 서버를 여러 개 구동시켜 클러스터화 시킬 수 있습니다. 여기서 앙상블은 영어 단어 그대로 협동한다는 의미입니다. 즉 클러스터(군집)를 이루어, 서로의 데이터를 복제하고 같이 협동합니다.
군집을 이루어 서로 협동하지만, 모두가 동등하지는 않습니다. zookeeper 클러스터는 leader, follower로 구성되는데요. 서버끼리 자동으로 leader, follower를 선출합니다.
이때 leader는 모든 상태 변화를 받아들이고 기록(write)합니다. 또한 오직 리더에만 기록 할 수 있습니다. follower들은 leader에 기록된 데이터를 읽고(read), 복제(replication)합니다.
2. 1) 2f + 1
zookeeper는 "2f + 1" 규칙을 따릅니다.
이는 "필요한 총 서버 = 2f + 1" 입니다. 그리고 f는 failure(정지, 고장)입니다.
예를 들어 총 3대의 클러스터 중 1대의 장애가 발생하더라도, 나머지 2대가 여전히 과반수를 이루고 있습니다. 그래서 의사결정이 가능합니다. 하지만 4대의 클러스터에 2대의 장애 발생 시 나머지 2대는 과반수를 이루지 못합니다.
3) Kafka Controller Broker
zookeeper는 리눅스의 파일 시스템과 유사합니다. 마치 트리처럼 생긴, 노드로서 데이터를 관리하는데요. 클라이언트 서비스들의 영속성 유지에 필요한 metadata를 노드에 파일로서 저장합니다. 그리고 이러한 노드들을 znode라고 부릅니다.
znode는 데이터의 의미를 이름으로 나타내고, 이를 이용해 계층을 구분합니다. 데이터의 변화가 있을 때마다 버전이 올라가는데요. 'znode', 'znode/v_1', 'znode/v_2'와 같이 증가합니다. 이때 특징은 디렉터리와 파일을 구분하지 않습니다. 리눅스의 파일 시스템과 유사할 뿐, 디렉터리와 파일을 모두 동등하게 다룹니다.
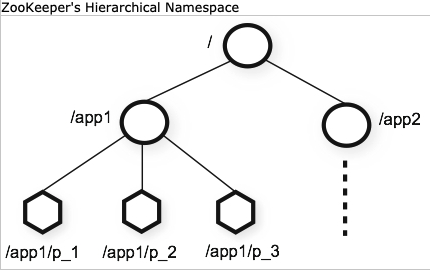
https://zookeeper.apache.org/doc/r3.3.2/zookeeperOver.html 갑자기 왜 kafka 컨트롤러 목록에서 zookeeper를 설명했을까요?
kafka 컨트롤러는 zookeeper에 의해 관리됩니다. 컨트롤러는 zookeeper에 의해 선출됩니다. 최초에 모든 브로커들은 zookeeper에 컨트롤러 노드로 등록 시도합니다. 이때 가장 먼저 '/controller' 노드로 등록되는 브로커가 컨트롤러가 됩니다.
컨트롤러 브로커는 아래와 같은 동작을 합니다.
- 토픽의 생성, 제거
- 토픽의 파티션 리더 선출
- 파티션 장애 관리
- 브로커 장애 관리
어떻게 zookeeper는 컨트롤러 브로커에 장애를 알려줄 수 있을까요?
각각의 브로커가 생성되면 znode로서 등록됩니다. 그리고 zookeeper는 꾸준히 ping을 보내 세션을 확인하는데요. 만약 장애가 발생하여 세션이 끊기게 된다면, 해당 노드를 삭제합니다. 그리고 삭제된 브로커를 컨트롤러에 알려줌으로서, 장애 브로커를 알려줄 수 있습니다.
그리고 컨트롤러는 알림을 확인 후 새로운 leader를 선출하고, 다시 회복된 브로커의 동기화를 관리합니다.
파티션 leader 선출 방식에 관한 것은 아래의 글을 참고하세요.
https://yeon-kr.tistory.com/183
4) 설정
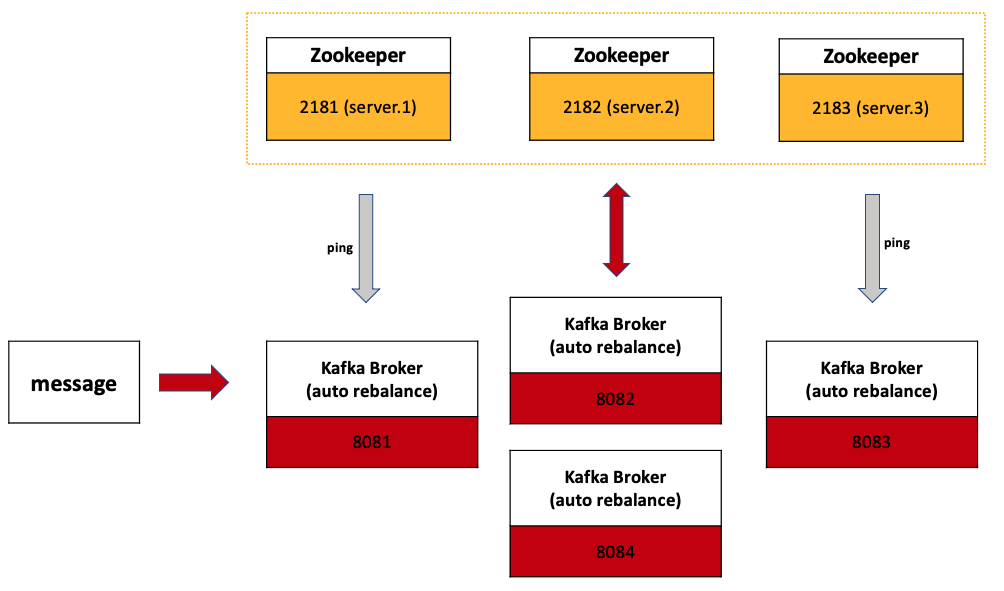
zookeeper 서버 3대 + 카프카 서버 4대 설정합니다.
4. 1) Zookeeper 설정
기존의 설정 파일을 복사하여, 3개로 만듭니다.
config/zookeeper[번호].properties
dataDir=/usr/local/var/lib/zookeeper/zookeeper[번호] ex) 2181 ~ 2183 clientPort=[포트번호] initLimit=5 syncLimit=2 ex) localhost:[port]:[port] server.1=localhost:2888:3888 server.2=localhost:2889:3889 server.3=localhost:2887:3887- dataDir
- 인메모리 데이터베이스의 스냅샷, 로그 디렉터리 (znode metadata)
- metadata는 메모리에 저장. 즉 종료 후 재시동 시 영속성 X --> dataDir 별도 필요
- 각 Zookeeper 서버마다 별도의 공간 필요
- initLimit: 초기에 팔로워가 리더의 데이터를 동기화하는 시간
- syncLimit: 해당 시간 동안 데이터를 싱크 하지 못하면, 클러스터에서 퇴출
- server.[번호]
- 각 서버마다 번호를 붙여줌
- dataDir에 "myId"라는 파일을 만들고, 서버 번호를 적어줘야 함
- ex) /zookeeper1/myId: $echo 1 > myid
- localhost:[port]:[port]
- zookeeper서버끼리 통신할 포트 (새 leader 선출 등)
- 다른 서버 사용 시 같은 2888:3888 사용 가능
- 현재는 학습용으로 하나의 서버에서 localhost로 구축
// Zookeeper 서버 실행 $ bin/zookeeper-server-start config/zookeeper[번호].properties4. 2) Kafka 설정
카프카 서버 4개를 실행합니다.
그림과 이전 글로 대체합니다.
https://yeon-kr.tistory.com/183
5) Test
새로운 토픽 생성, 정보를 확인합니다.
// "test" 토픽 생성 $ kafka-topics --create --zookeeper (연속) localhost:2181,localhost:2182,localhost:2183 (연속) --replication-factor 4 --partitions 10 --topic test- "test" 토픽 생성
- 4개의 replication 그룹 생성
- 2181 ~ 2183까지 3개의 주키퍼 서버 사용
// 현재 토픽 정보 $ kafka-topics --describe --zookeeper localhost:2181,localhost:2182,localhost:2183 Topic: test TopicId: JNzi3mkbQqG0P6AEwPiATA PartitionCount: 10 ReplicationFactor: 4 Configs: Topic: test Partition: 0 Leader: 3 Replicas: 3,2,4,1 Isr: 3,2,4,1 Topic: test Partition: 1 Leader: 4 Replicas: 4,3,1,2 Isr: 4,3,1,2 Topic: test Partition: 2 Leader: 1 Replicas: 1,4,2,3 Isr: 1,4,2,3 Topic: test Partition: 3 Leader: 2 Replicas: 2,1,3,4 Isr: 2,1,3,4 Topic: test Partition: 4 Leader: 3 Replicas: 3,4,1,2 Isr: 3,4,1,2 Topic: test Partition: 5 Leader: 4 Replicas: 4,1,2,3 Isr: 4,1,2,3 ... 생략- 토픽 생성 후 정보
5. 1) 컨트롤러 브로커 장애 발생 시
// 현재 컨트롤러 브로커 보기 $ /bin zookeeper-shell [zookeeper ip] get /controller // 현재 controller {"version":1,"brokerid":1,"timestamp":"1631876996515"}- 현재 zookeeper에 등록된 컨트롤러 브로커: 1번
// 1번 브로커 종료 Topic: test TopicId: JNzi3mkbQqG0P6AEwPiATA PartitionCount: 10 ReplicationFactor: 4 Configs: Topic: test Partition: 0 Leader: 3 Replicas: 3,2,4,1 Isr: 3,2,4 Topic: test Partition: 1 Leader: 4 Replicas: 4,3,1,2 Isr: 4,3,2 Topic: test Partition: 2 Leader: 4 Replicas: 1,4,2,3 Isr: 4,2,3 Topic: test Partition: 3 Leader: 2 Replicas: 2,1,3,4 Isr: 2,3,4 Topic: test Partition: 4 Leader: 3 Replicas: 3,4,1,2 Isr: 3,4,2 Topic: test Partition: 5 Leader: 4 Replicas: 4,1,2,3 Isr: 4,2,3 ... 생략- 1번 브로커(컨트롤러) 종료
- 주키퍼 의해 새로운 리더 선정
- 1번 브로커(컨트롤러) ISR 그룹 퇴출
// 1번 브로커 종료 후 현재 컨트롤러 브로커 $ zookeeper-shell localhost:2181,localhost:2182,localhost:2183 get /controller {"version":1,"brokerid":4,"timestamp":"1631878568006"}- 기존 컨트롤러: 1번 브로커
- 1번 종료 후 컨트롤러: 4번 브로커 새로 선출
// 1번 브로커 다시 실행 $ kafka-topics --describe --zookeeper localhost:2181,localhost:2182,localhost:2183 Topic: test TopicId: JNzi3mkbQqG0P6AEwPiATA PartitionCount: 10 ReplicationFactor: 4 Configs: Topic: test Partition: 0 Leader: 3 Replicas: 3,2,4,1 Isr: 3,2,4,1 Topic: test Partition: 1 Leader: 4 Replicas: 4,3,1,2 Isr: 4,3,2,1 Topic: test Partition: 2 Leader: 4 Replicas: 1,4,2,3 Isr: 4,2,3,1 Topic: test Partition: 3 Leader: 2 Replicas: 2,1,3,4 Isr: 2,3,4,1 Topic: test Partition: 4 Leader: 3 Replicas: 3,4,1,2 Isr: 3,4,2,1 Topic: test Partition: 5 Leader: 4 Replicas: 4,1,2,3 Isr: 4,2,3,1 ... 생략- 종료된 1번 브로커 재실행
- 다시 ISR 그룹 합류
5. 2) zookeeper 클러스터 leader 장애 시
$ bin echo srvr | nc localhost 2181 | grep Mode Mode: follower $ bin echo srvr | nc localhost 2182 | grep Mode Mode: leader $ bin echo srvr | nc localhost 2183 | grep Mode Mode: follower- 현재 leader: 2182 (2번)
// 2번 주키퍼(리더) 종료 후 $ bin echo srvr | nc localhost 2181 | grep Mode Mode: follower $ bin echo srvr | nc localhost 2183 | grep Mode Mode: leader- 기존 leader: 2181 (2번)
- 2번 zookeeper 종료 후 리더: 2183 (3번)
// 2번 zookeeper 재실행 $ zookeeper-server-start -daemon /usr/local/Cellar/kafka/2.8.0/libexec/config/zookeeper2.properties // 2번 zookeeper 현재 상태 $ echo srvr | nc localhost 2182 | grep Mode Mode: follower- 2번 zookeeper 재실행 --> follower mode
6) 참고 문헌
https://dattell.com/data-architecture-blog/what-is-zookeeper-how-does-it-support-kafka/
https://data-flair.training/blogs/zookeeper-in-kafka
반응형'Kafka' 카테고리의 다른 글
Kafka 클러스터 메세지 발행 및 문제 해결 (0) 2021.10.04 Kafka 클러스터 구성 및 장애 해결 (0) 2021.09.12 (Kafka) 객체를 JSON 타입으로 넘겨보자 (0) 2021.09.01 Kafka, @Async 비동기 처리 맛보기 (4) 2021.08.16