-
Stream은 일회용품이다.Java & Kotlin 2021. 12. 12. 23:16반응형
1. 서론
코딩, 프로그래밍을 하는 데에는 각자의 취향이 분명 있을 것입니다. 하지만 무엇이 옳다고 말할 수는 없는데요.
다양한 프로그래밍 방식 중 저는 무엇인가를 조회할 때 각각 변수에 담아, 다시 사용하는 것을 좋아합니다.
JPA에서 사용되는 쿼리 메서드를 예로 들겠습니다.
누군가는 애초에 변수 b만 들어서, a의 내용을 join으로 한 번에 가지고 오기도 합니다. 혹은 변수 자체를 만들지 않고, 바로 return에 조회하는 메서드를 사용하기도 합니다.
하지만 저는 세번째와 같이 변수에 하나하나 담아, return 하는 방식을 선호하는데요. 이유는 각각의 의도를 가진 변수명을 사용해서, 어떤 목적을 가지고 있는지 명확히 알 수 있습니다. 또한 어떤 부분에서 에러가 발생하는지 명확히 파악할 수도 있습니다.
B b = find(); // join 사용하여 A까지 한번에 return b; ------------------------------------------- return find(); // 바로 return ------------------------------------------- // 변수 a, b 각각 저장 후 return A a = findByIdx(int idx); B b = findByA(A a); return b;물론 이러한 방식은 코드가 길어진다는 단점도 존재합니다. 하지만 명식적으로 파악할 수 있다는 점에서 매우 선호합니다.
하지만 최근 Stream을 사용하며 해당 방식을 사용할 수 없었는데요. 왜 안되는지 공부하려고 합니다.

Strem은 ONE-SHOT!
2. Stream은 재활용되지 않는다
아래의 코드는 list에 담긴 a ~ d를 대문자 A ~ D로 변경 후 출력합니다.
public class StreamTest { public static void main(String[] args) { List<String> list = new ArrayList<>(); list.add("a"); list.add("b"); list.add("c"); list.add("d"); list.stream() .map(String::toUpperCase) .forEach(System.out::println); } }
정상적으로 출력이 잘 됩니다.
하지만 아래와 같은 상황은 어떨까요?
public class StreamTest { public static void main(String[] args) { List<String> list = new ArrayList<>(); list.add("a"); list.add("b"); list.add("c"); list.add("d"); // List --> Stream Stream<String> listStream = list.stream(); // B 제외 출력 List<String> exceptB = listStream .map(String::toUpperCase) .filter(S -> !S.equals("B")) .collect(Collectors.toList()); exceptB.forEach(System.out::println); System.out.println("-----------------"); // 전체 다 출력 (listStream 재활용) List<String> all = listStream .map(String::toUpperCase) .collect(Collectors.toList()); all.forEach(System.out::println); } }두 가지 목적의 Stream이 존재합니다.
- B 제외한 값들 출력
- A ~ D 모두 출력
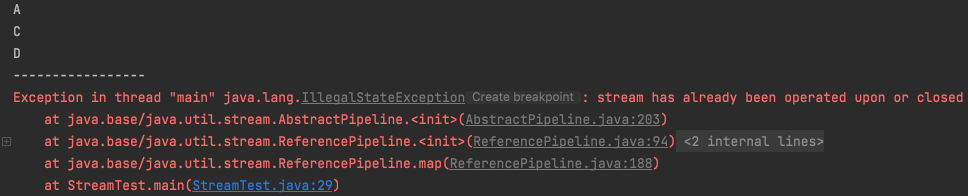
한번 Stream으로 만든 listStream을 다양한 방식으로 재활용하려고 했습니다. 하지만 이미 한 번 사용된 stream은 더 이상 사용할 수 없다는 에러가 발생합니다.
왜 그럴까요?
3. 왜 재사용이 안될까?
우선 Java API 문서입니다.
Interface Stream<T>
A stream should be operated on (invoking an intermediate or terminal stream operation) only once. This rules out, for example, "forked" streams, where the same source feeds two or more pipelines, or multiple traversals of the same stream. A stream implementation may throw IllegalStateException if it detects that the stream is being reused.스트림은 단 한 번만 동작되어야 한다고 합니다. 만약 하나의 같은 자원을 여러 개의 파이프라인을 통해서 사용된다면, IlleagalStateException을 발생시킨다고 합니다.
재사용이 안 되는 것은 알겠습니다. 다만 "왜?"라는 질문에는 충분한 답변이 되지 못합니다.
그래서 열심히 구글링을 하던 도중 StackOverFlow에 stuart marks의 댓글을 찾았습니다. stuart marks는 openJDK팀에서 일하며, Stream을 만들 때 참여했던 엔지니어인데요. 당시의 고민을 댓글을 통해 알 수 있습니다.
Our prototype design at the time was based around Iterable. The familiar operations filter, map, and so forth were extension (default) methods on Iterable.
Since these are Iterables, you can call the iterator() method more than once. What should happen then?최초에 만들 때는 Iterable에 기반을 두고 만들었다고 합니다. 그리고 iterater()는 반복해서 호출할 수 있듯이 Stream도 마찬가지로 생각을 했다고 하는데요.
If the source is a collection, this mostly works fine. Collections are Iterable, and each call to iterator() produces a distinct Iterator instance that is independent of any other active instances, and each traverses the collection independently. Great.
대부분의 반복하려는 대상은 Collections이기 때문에 이 부분에서는 아무런 문제가 없었다고 합니다.
Now what if the source is one-shot, like reading lines from a file? Maybe the first Iterator should get all the values but the second and subsequent ones should be empty. Maybe the values should be interleaved among the Iterators. Or maybe each Iterator should get all the same values. Then, what if you have two iterators and one gets farther ahead of the other? Somebody will have to buffer up the values in the second Iterator until they're read. Worse, what if you get one Iterator and read all the values, and only then get a second Iterator. Where do the values come from now? Is there a requirement for them all to be buffered up just in case somebody wants a second Iterator?
하지만 "만약에 조회하려는 자원이 one-shot(1회성의) 일 때는 어떻게 될까?"라는 질문을 던집니다. 앞서 stuart marks는 Stream이 단순히 Collections뿐만 아니라, 네트워크의 자원과 파일까지 다양한 형식까지 읽어 들이는 것을 고려했다고 밝혔었습니다.
예를 들어 대상이 되는 자원이 one-shot이라면, 첫 번째 Stream이 한 줄을 읽었을 때 두 번째 Stream이 읽을 해당 줄은 empty일 것입니다.
Clearly, allowing multiple Iterators over a one-shot source raises a lot of questions. We didn't have good answers for them. We wanted consistent, predictable behavior for what happens if you call iterator() twice. This pushed us toward disallowing multiple traversals, making the pipelines one-shot.
즉 one-shot 자원이 empty일 때 어떻게 처리할 것인지에 대해서 명확한 해결책을 찾아내지 못했다고 합니다. 그래서 iterable, one - shot 자원들에 대해서 일관성 있고, 예측 가능한 동작을 위해 아얘 한 번만 사용 가능하게 만들었다고 합니다.
4. 정리
openJDK 측에서 Stream을 만들면서 많은 고민을 한 것이 느껴집니다.
기본적으로 Iterable처럼 반복하려는 의도가 보였습니다. 하지만 단순히 반복하는 것에서 그치지 않습니다. 가공, 필터, 반복 등의 method chaining을 통해 대량의 데이터를 다루려고 하는 것이 보입니다. 또한 단순히 소스 상의 자원뿐만 아니라, 파일이나 네트워크의 정보들까지 활용하려는 의도가 보입니다.
사실 Stream에서 파이프라인(pipeline)이라는 내용이 자주 보입니다. 데이터가 파이프라인을 통해 흘렀다면, 더 이상 없는 것이 어찌 보면 당연하게 보이기도 합니다.
그동안 Stream은 왜 재사용이 되지 않을까 고민을 했었지만, 만들 당시의 배경과 고민을 알고 나니 명확히 이해할 수 있어서 좋았습니다.
반응형'Java & Kotlin' 카테고리의 다른 글
착한 가로채기, InterruptedException (0) 2022.02.21 [Intellij] Google Java auto-formatting 적용 (0) 2022.02.07 그래서 예외처리는요? (0) 2021.12.05 @Async, 생각보다 까다롭다. (2) 2021.11.01 인터페이스의 default, static 메소드 (0) 2021.10.06