-
Spring Cloud Sleuth + logback 적용기Spring Framework 2023. 2. 1. 20:06반응형
1) 서론
기존의 단일 모듈로 구성되어 있던 것을 MSA로 분리하면서 로그 추적이 매우 힘들어진 것을 경험했습니다. 이전에는 하나의 클라이언트 요청에 대해서 하나의 서버에서만 처리를 담당했습니다. 다연히 트랜잭션을 잘 확인한다면 전체 로그 추적이 어렵지 않았는데요.
MSA로 분리하게 되면서 하나의 클라이언트 요청에 대해 서버 - 서버 통신이 아주 많이 발생하고 있습니다. 여러개의 서버를 요청하여 하나의 클라이언트 응답으로 만들어 주는 경우가 늘어났습니다.
위와 같이 여러 서버를 통신했을 때 각 서버의 요청은 별도의 트랜잭션으로 동작합니다. 이 때문에 하나의 서버에서 오류가 발생했을 때 전체 흐름을 추적하기 힘들어집니다.
특히 멀티 쓰레드를 활용하여 다수의 요청이 발생하게 되면 더더욱 파악하기 어려워집니다.
이러한 불편함을 개선할 수 있는 Spring Cloud Sleuth 적용기 공유드립니다.
2) Spring Cloud Sleuth란
Spring Cloud Sleuth는 분산 로그 추적기입니다.
아래의 사진은 하나의 클라이언트 요청에 대해서 여러 서버를 거치는 것을 나타내고 있는데요. MSA에서는 하나의 클라이언트 요청에 대해서 여러 서버버간의 요청/응답을 통해 최종 클라이언트에게 응답을 전달합니다.
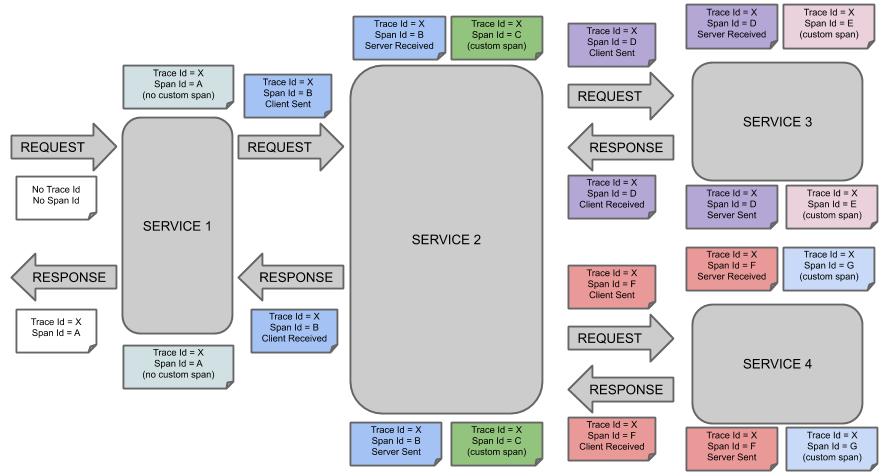
출처: https://docs.spring.io/spring-cloud-sleuth/docs/current/reference/html/getting-started.html#getting-started 이때의 문제점은 서버간의 트랜잭션이 별도로 관리된다는 것인데요. service1에서 정상이었지만, service2에서 예외가 발생했을 때 두 개의 트랜잭션 로그가 동일한 요청인지 파악할 수 없게 됩니다.
그래서 sleuth는 trace, span을 이용해서 분산 로그 추적을 합니다.
- span: 하나의 작업에 대한 단위입니다. 각 트랜잭션별로 고유한 id를 가집니다
- trace: 여러 개의 span을 가진 tree 형태의 구조입니다. 전체 요청에 대해서 고유한 id를 가집니다
위의 사진을 봤을 때 하나의 요청에 대해서 trace id는 고유한 X를 가지지만, span id는 계속해서 변하는 것을 볼 수 있습니다. 만약 클라우드를 사용하여 전체 서버에 대한 통합 로그를 보는 것이 가능하다면 trace id 하나로 전체 서버의 흐름을 볼 수 있습니다.
3) 실제 적용하기
테스트를 위해 서버를 여러대 띄우지는 않겠습니다. 멀티 쓰레딩을 통해서 여러 요청에 대한 로그를 섞이게 한 뒤 추적하는 것으로 테스트해보겠습니다.

- 기본적인 logback 설정입니다


- service1에서 service2를 비동기로 호출합니다.

- 호출된 service2에서 로그를 출력합니다.
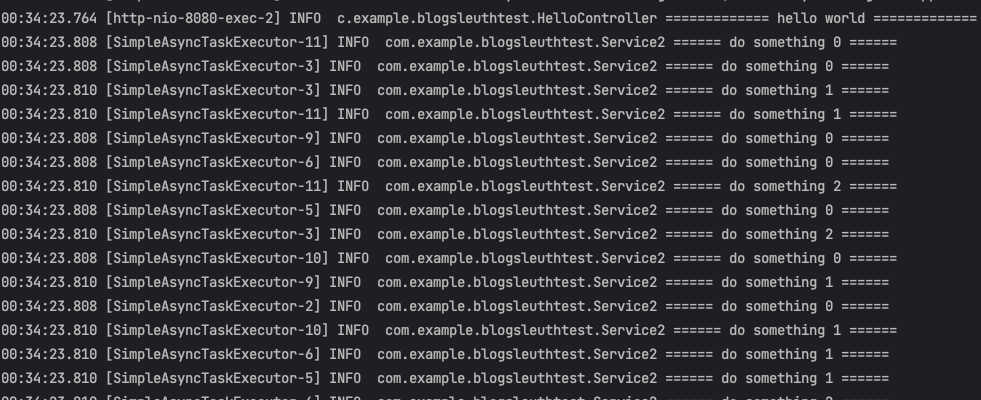
수행했을 때의 로그는 하나의 클라이언트에 의해서 수행되는 것인지 파악하기 어렵습니다. 하나의 요청에 대해서 멀티 스레드로 동작하며 각각의 exectuor 번호들만 기록에 남게 되는데요.
만약 이러한 요청이 수백만 건이고 시스템 예외가 발생했을 때는 정말 추적하기 어려울 것입니다.
4) Sleuth 설정 및 테스트
implementation 'org.springframework.cloud:spring-cloud-starter-sleuth<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender"> <encoder> <pattern>%d{HH:mm:ss.SSS} [%thread] %-5level %logger{40} [traceId:%X{traceId:-} spanId:%X{spanId:-}] %msg%n</pattern> </encoder> </appender>- sleuth 의존성 추가합니다
- %X{traceId:-}, %X{spanId:-}
- %X는 logback에서 지원하는 클래스이며 스레드당 문맥 정보를 맵핑해 주는 역할합니다

- 클라이언트 요청 시작과 비즈니스 로직의 'traceId(bre83dfdaf788aae)'는 동일합니다
- 각 비즈니스 로직은 별도의 스레드로 동작하기 때문에 'spanId(ccb18d58d58ca6d6)'는 다릅니다

- Exception이 발생하더라도 어떤 요청에 의해서 발생했는지 추적 가능합니다.
만약 클라우드에서 지원되는 로깅 시스템(e.g. GCP Cloud Logging)을 사용한다면 logback 설정은 생략하셔도 좋습니다. 대부분의 클라우드의 로깅 시스템은 sleuth 의존성을 추가하는 것만으로 traceId, spanId 등의 정보를 잘 수집해서 보여줍니다.
핀테크 혹은 금융권에서는 일정 부분의 제약으로 인해 온프레미스를 반드시 사용할 수밖에 없는데요. 만약 이렇게 온프레미스와 클라우드를 함께 사용하는 환경이거나, 로컬 테스트시에는 logback 설정을 참고하여 사용하면 될 것 같습니다.
5) 결론
그동안 하나의 repository, 하나의 서버로 구성된 환경에서 개발을 했었는데요. MSA 여러 개의 repository와 서버들로 분리하면서 많은 어려움이 있었습니다. 그중에서도 로그를 추적하기가 매우 어려웠었습니다.
Sleuth 의존성을 간단하게 추가함으로써 전체 서버에 대한 로그 추적이 용이해졌습니다. 특히 온프레미스 환경에서도 logback 설정을 통해 쉽게 로그를 추적을 할 수 있게 된 것이 좋았습니다.
6) 참고문헌
반응형'Spring Framework' 카테고리의 다른 글
JPA Repository 기본 postfix로 인한 순환참조 해결 (0) 2023.07.30 식탁위의 메뉴판, Local cache invalidate (0) 2023.05.10 스프링에서 재처리를 위한 @Retryable 사용하기 (3) 2022.08.22 Junit 테스트 병렬 수행으로 빌드 시간 단축하기 (0) 2022.08.16 Querydsl cross join 개선 하기 (0) 2022.06.18